Cellular Control
Gene Expression
All cells of our body contain the same set of genes but can have very different structures and functions in our body. The reason that a brain cell is so much different from a muscle cell is because different proteins are being made - this results from the activation (and deactivation) of different genes in these two cells.
Within each cell, certain genes will be activated, and others will be inactivated. Only the activated genes are transcribed into mRNA which is translated into protein. The proteins that are formed will modify the cell by changing its structure and controlling cellular processes. These changes cause the cell to become specialised.
For example, during the differentiation of a stem cell into a red blood cell, certain genes are activated. These genes are responsible for the production of haemoglobin and of proteins which will destroy the nucleus (enabling the cell to pack in more haemoglobin). Other genes will be inactivated so that any proteins which are unrelated to the functioning of red blood cells will not be produced. The production of red blood cell-related proteins will modify the cell, resulting in a specialised red blood cell.
Transcription Factors
The activation and deactivation of genes is carried out by proteins called transcription factors (TFs). TFs which activate genes are called activators whereas TFs which deactivate genes are referred to as repressors. Activators can work by binding to the beginning of the gene (the promoter region) and helping RNA polymerase to bind and transcribe the gene. Repressors can work by binding to the gene and blocking RNA polymerase from binding.
Operons
In prokaryotes, transcription factors bind to regions of DNA called operons. An operon is a section of DNA that contains a cluster of genes which are controlled by a single promoter (regulatory region). Operons contain the following elements:
Structural genes - these code for useful proteins such as enzymes
Control elements - these contain a promoter region where RNA polymerase can bind and an operator region where transcription factors can bind
Regulatory gene - these codes for transcription factors (activators or repressors).
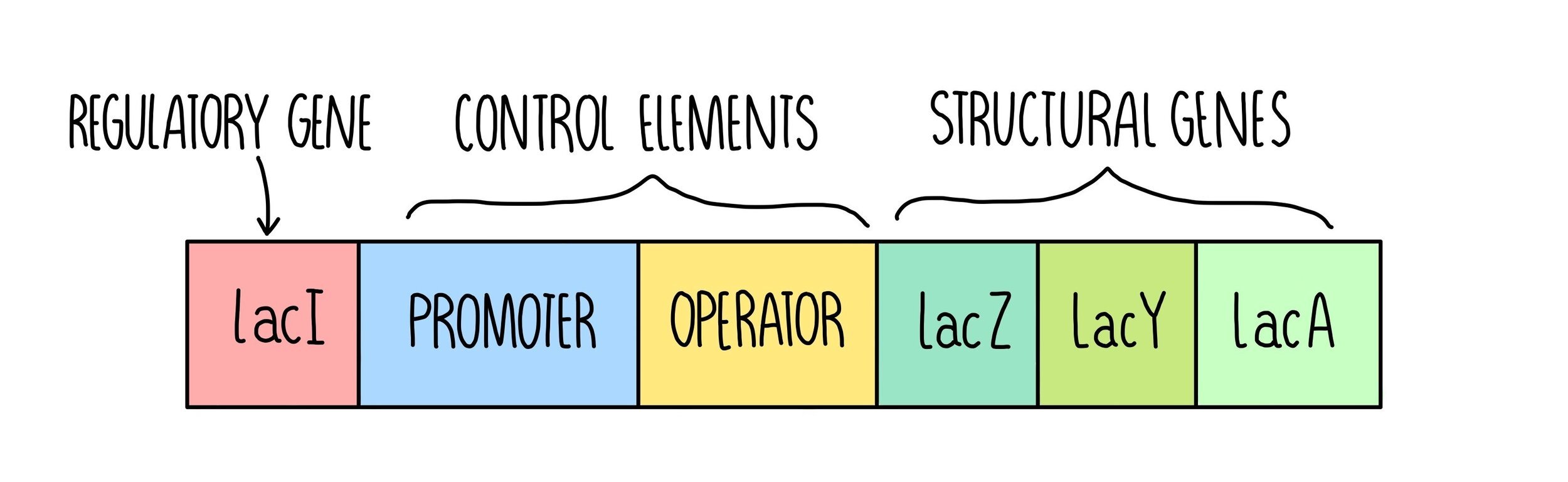
Lac Operon
E. coli are a species of bacteria which feed on glucose. When glucose is not available, they can digest lactose. E. coli only produce the enzymes to digest lactose when glucose is absent (and lactose is present), so that they don’t waste energy and resources building proteins that they don’t need. The genes which produce the enzymes to respire lactose are found on an operon called the lac operon.
When lactose is absent, a regulatory gene (lacI) produces a protein called the lac repressor. The lac repressor is a transcription factor which binds to the operator region. This blocks RNA polymerase from binding to the promoter region, so the structural genes are not transcribed.
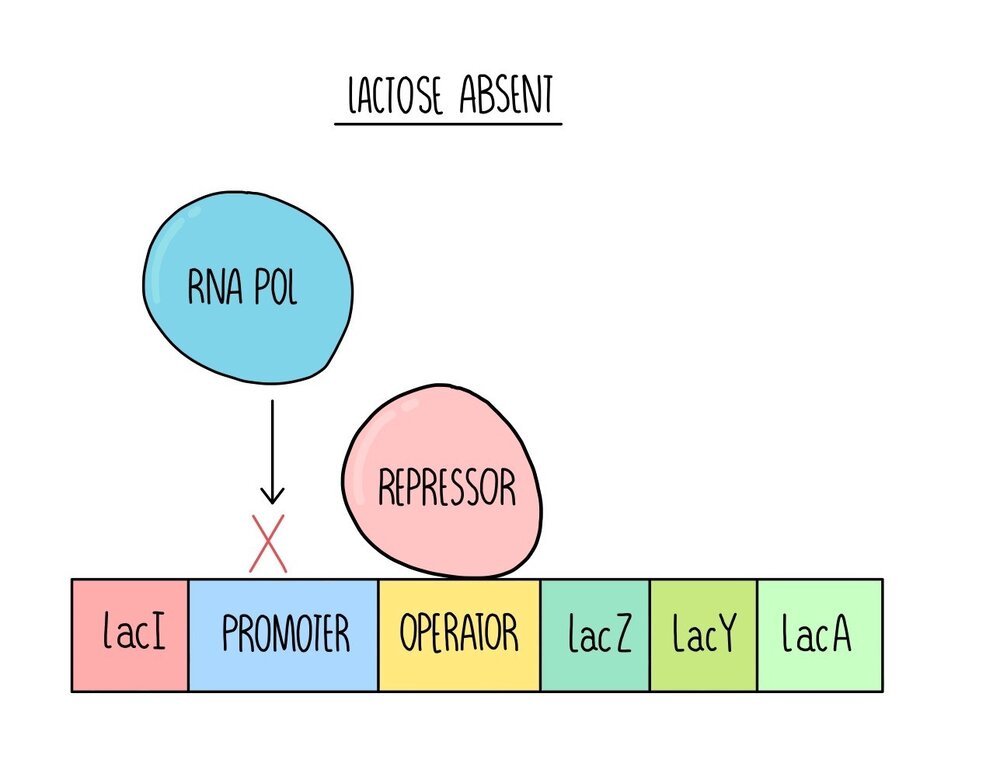
When lactose is present, lactose binds to the repressor and changes its shape. This shape change means that the repressor can no longer bind to the operator, allowing RNA polymerase to bind to the promoter region. RNA polymerase transcribes the structural genes - lacZ, lacY and lacA. These genes code for proteins which allow E. coli to respire lactose. LacZ codes for an enzyme called beta-galactosidase which breaks the glycosidic bond in lactose, breaking it down into glucose and galactose. Lac Y codes for a protein called lactose permease, a membrane protein which transports lactose into the cell. Scientists still aren’t sure what the function of the lacA gene is and its exact role in digesting lactose.

Splicing – post-transcriptional control
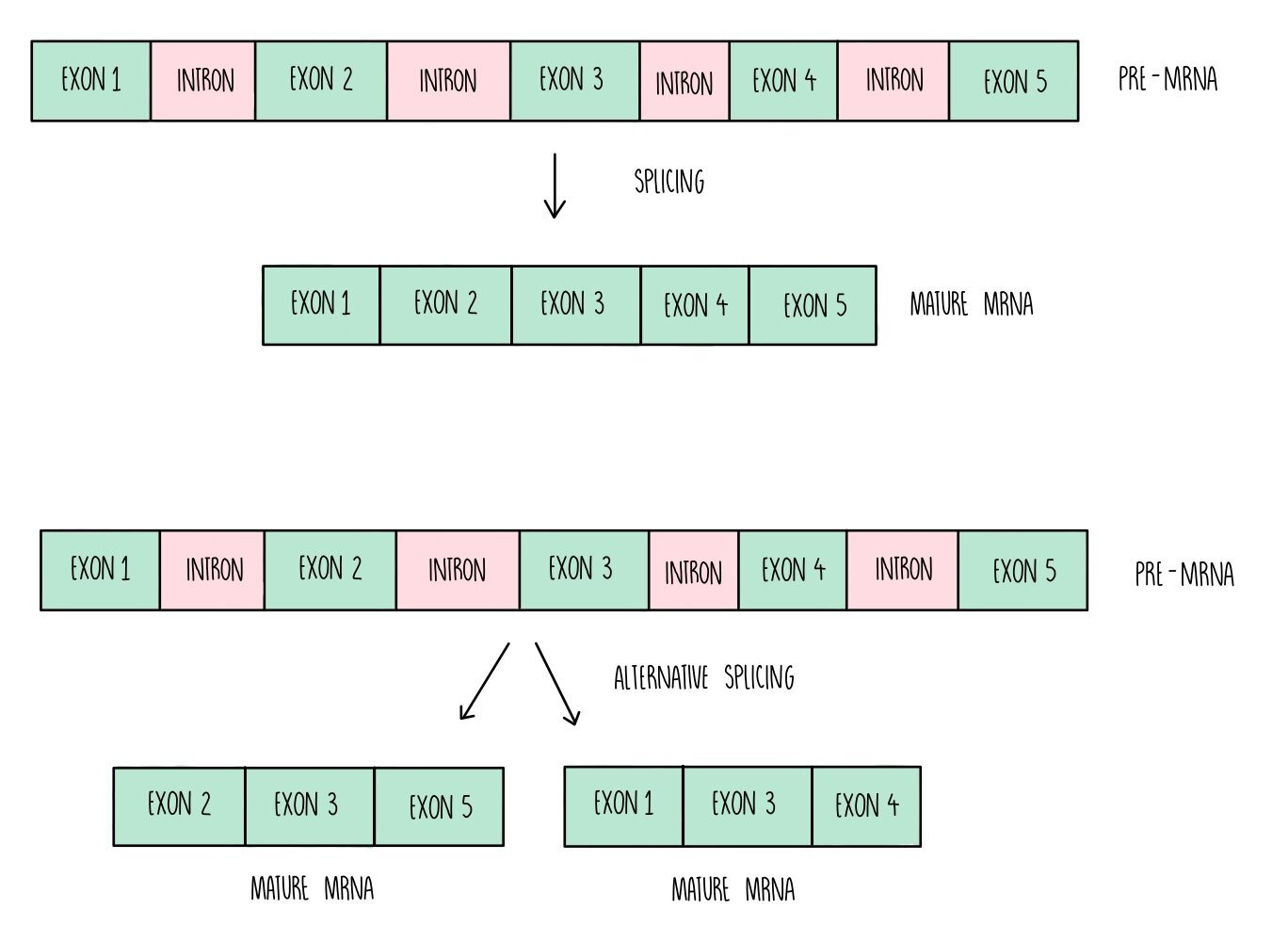
The genome is the complete set of genes present in a cell (or organism). Only a small proportion of the DNA within the genome contains the instructions for making proteins. Within a gene, there are sections of DNA known as introns which don’t code for amino acids. These are removed from the mRNA before translation in a process called splicing. This only occurs in eukaryotes – prokaryotic DNA doesn’t contain introns.
cAMP – post-translational control
Some proteins are synthesised in an inactive form and need to be activated to be fully functional. Protein activation is controlled by molecules such as hormones, which bind to receptors on the cell membrane and trigger the production of a second messenger molecule called cyclic AMP (cAMP). cAMP activates proteins by changing their 3D structure. For instance, cAMP binds to protein kinase A (PKA), an important enzyme in cell signalling reactions. In the inactive form, PKA is a tetramer of four subunits but upon cAMP binding it dissociates into two active dimers.
Development of the body plan – Hox genes
The body plan refers to the general organisation of an organism’s body – i.e., the head at the top, feet at the bottom, arms/wings/tentacles at the sides. The arrangement of different body parts is controlled by a group of genes called Hox genes. These genes are highly conserved, which means that their DNA sequences have hardly changed through evolution. This highlights their importance – if a mutation occurs, it has such a detrimental effect on the organisms that it is unlikely to be passed on to the next generation.
Hox genes are transcribed and translated into Hox proteins. A special region on the hox protein, known as the homeodomain, acts as a DNA-binding site. Hox proteins bind to DNA, switching certain genes on and repressing others, acting as transcription factors. For instance, in cells that are fated to become the feet, Hox proteins will activate genes that form the toes, hair follicles, toenails and turn off genes that are form the eyes.
Development of the body plan – apoptosis and mitosis
Mitosis and apoptosis also play a role in the development of the body plan. Mitosis is needed to create the bulk of the body parts, generating enough cells to fill the body. Apoptosis then chisels away at the mass of cells, forming structures such as fingers and toes.
Depending on the cell, genes that control apoptosis might be switched on and those that trigger mitosis are switched off. In other cells, it will be the other way around.

Apoptosis of a mouse fat cell. Credit Evilonan (Wikipedia)
Apoptosis is the process of ‘controlled cell death’, where cells annihilate themselves without making a mess. First, enzymes are activated that break down the components of the cell, including DNA and proteins. The cell then shrinks, fragments and the cellular debris is phagocytosed by macrophages.
Genes that control apoptosis can be activated by internal stimuli (such as DNA damage) and external stimuli (like pathogenic infection).
Types of mutation
Any change to the base sequence of DNA is called a mutation. There are various types:

Substitution - one base is replaced for another e.g. TGCCTA becomes TGACTA. It results either in a change to a single amino acid, or the amino acid might stay the same because more than one codon can code for the same amino acid (the genetic code is degenerate).
Insertion - one or more bases is added e.g. TGCCTA becomes TGCCCTA. This type of mutation will change the codon (and perhaps the amino acid) and all following codons (this is called a frameshift).
Deletion - one or more bases is removed e.g. TGCCTA becomes TGCTA. Deletion mutations will change the codon at the point of mutation and all following codons, resulting in a frameshift.
Inversion - a sequence of bases is reversed e.g. TGCCTA becomes TGCATC. It will result in a change to a single amino acid.
Some mutations can have a neutral effect on a protein’s function. This could be because:
The mutation changes a base in a triplet but the amino acid that the triplet codes for doesn’t change. This happens because some amino acids are coded for by more than one triplet (the genetic code is degenerate).
The mutation produces a triplet that codes for a different amino acid but the amino acid is chemically similar to the original so it functions like the original amino acid.
The mutated triplet codes for an amino acid not involved with the protein’s function e.g. one that is located far away from an enzyme’s active site, so the protein works as it normally does.
However, some mutations will have an effect and it could be beneficial or harmful to the organism. In these cases, the mutated allele produces a protein with an altered tertiary structure, due to changes in protein’s primary structure (i.e. a different order of amino acids).
An example of a beneficial mutation is antibiotic resistance in bacteria (from the bacteria’s perspective). The mutation would allow it to survive in the presence of the antibiotic whereas it would have previously been killed. Other mutations will have harmful effects, such as the mutations which cause cystic fibrosis or cancer.